多项式拟合
问题简述
拟合数据点 $\hat{y_j}$ $$ \hat{y_j} = \sum_{i=0}^{n-1} \omega_i * x_j^i $$
拟合 $m$ 个数据点,并写成向量的形式
$$ \hat{\boldsymbol{y}} = \mathbf{X} \cdot \boldsymbol{\omega} $$
其中
$$ \mathbf{X} = \begin{bmatrix} 1 & x_1 & \cdots & x_1^{n-1} \\ 1 & x_2 & \cdots & x_2^{n-1} \\ \vdots & \vdots & & \vdots \\ 1 & x_m & \cdots & x_m^{n-1} \end{bmatrix} $$
程序设计
Note
输入: $m$ 个相异的数据点 $(\boldsymbol{x}, \boldsymbol{y})$
输出: $\boldsymbol{\omega}$
# fake data
x = np.linspace(-2, 2, 150)
y = np.exp(x/2.0)*np.power(x, 3) + 2.0*np.random.randn(len(x))
x = np.reshape(x, (x.shape[0], 1))
y = np.reshape(y, (y.shape[0], 1))
# Visualization
plt.figure(figsize=(18, 10))
mngr = plt.get_current_fig_manager()
mngr.window.wm_geometry("+50+310")
plt.suptitle('Regression', fontsize=20)
for n in range(1, 7):
plt.subplot(2,3,n)
X = np.ones((x.shape[0], 1))
for i in range(n): X = np.hstack((np.power(x, i+1), X))
w = np.random.randn(X.shape[1], 1)
mat = regression(y, X, w=w, n=n, lr=0.4, lam=10, stop_condition=1e-3)
w, mu, std = mat.train()
 ◎ 回归
◎ 回归
 ◎ 回归
◎ 回归Numpy VS PyTorch
$$ y^{(i)} = w_1x_1^{(i)} + w_2x_2^{(i)} + b $$
num_inputs = 2 # w1, w2
num_examples = 1000 # 样本容量
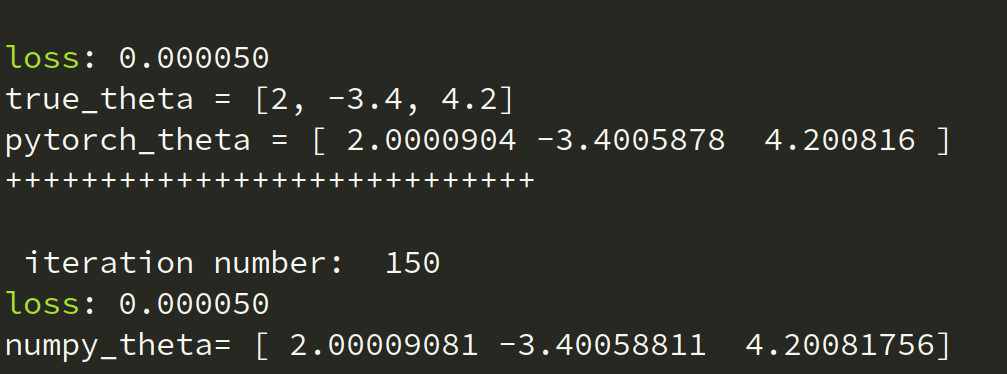
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,
dtype=torch.float32) # 特征(1000, 2)
labels = true_w[0]*features[:,0] + true_w[1]*features[:,1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32) # 标签(1000, 1)

PyTorch
# 初始化参数
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)),
dtype=torch.float32, requires_grad=True)
b = torch.zeros(1, dtype=torch.float32, requires_grad=True)
# 训练数据
lr = 0.1
num_epochs = 150 # 进行 150 步
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
X, y = features, labels
l = loss(net(X, w, b), y).sum()
l.backward()
sgd([w, b], lr, batch_size=1000)
w.grad.data.zero_()
b.grad.data.zero_()
train_l = loss(net(features, w, b), labels)
Numpy
# tensor --> numpy
features_numpy = np.reshape(features.numpy(), (num_examples, num_inputs))
labels_numpy = np.reshape(labels.numpy(), (num_examples, 1))
# 最后增加一列 1
features_numpy = np.hstack((features_numpy, np.ones((num_examples, 1))))
w = np.random.normal(0, 0.01, (num_inputs, 1))
w = np.vstack((w, [0]))
mat = linear_regression(labels_numpy, features_numpy, w=w,
lr=0.1, lam=0, MAX_Iter=150, stop_condition=1e-8)
loss, w = mat.train()